“The tangram (Chinese: 七巧板; pinyin: qī qiǎo bǎn; literally “seven boards of skill”) is a dissection puzzle consisting of seven flat shapes, called tans, which are put together to form shapes. The objective of the puzzle is to form a specific shape (given only an outline or silhouette) using all seven pieces, which may not overlap.”
http://en.wikipedia.org/wiki/Tangram
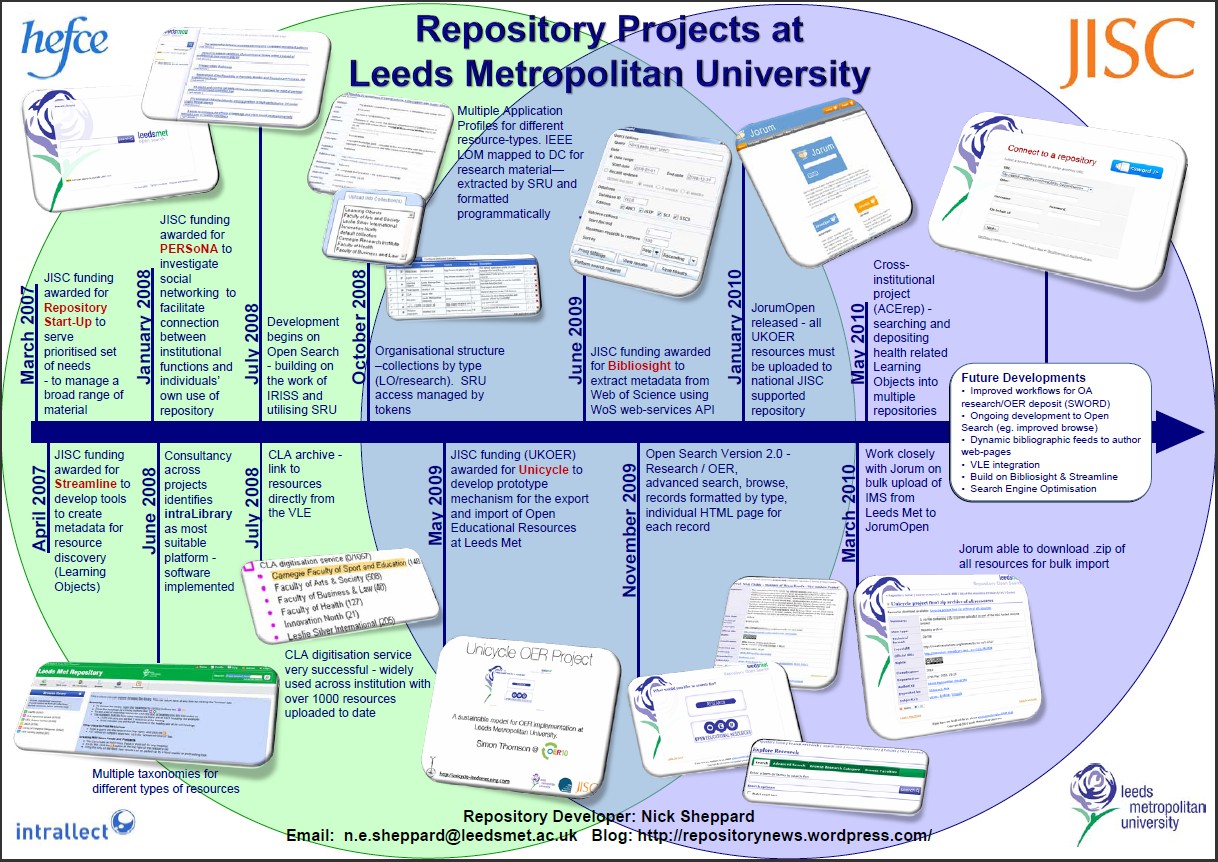
Having implemented an institutional repository at Leeds Metropolitan and learning by experience some of the difficulties associated with advocacy around the use of that repository (both for OA research and OER) I have become all too aware “that repositories are ‘lonely and isolated’; still very much under-used and not sufficiently linked to other university systems”. So said JISC’s Andy McGregor at an event called “Learning How to Play Nicely: Repositories and CRIS” in May 2010 at Leeds Metropolitan (see my report for Ariadne here). This quote is still relevant, though perhaps a little less so than when I heard it nearly 2 years ago, thanks to the ongoing work of JISC and particularly the RSP. In any case, the event was a revelation for me and I have coveted a so called Current Research Information Management systems (or CRIS for short) ever since!
And now, in Symplectic Elements, I have one…or at least the components of one (click on image for full size.)

The finished tangram? (click on image for full size)
It’s a puzzle though. A tangram if you will…one with considerably more than seven pieces:
intraLibrary, Symplectic, institutional website, University Research Office (URO), faculty research administrators, The Research Excellence Framework (REF), academic staff, web-developers, bibliographic information, research outputs, Open Educational Resources (OER)…
In fact, this may well not be all the pieces…pretty sure a few have been pushed down the back of the settee. I’ll look for them later.
Anyway, tortured metaphors aside, I have become increasingly aware that working in a large institution, in a role that encompasses technology and institutional policy (though I’m not, by any means, a policy maker…or indeed a real techie) is largely about communication and getting the right people, with the right skills, in the right place at the right time! Absorb policy and technical requirements from senior stakeholders and communicate those requirements to the proper techies – while also trying to ensure any motivating passions of one’s own don’t get lost along the way – Open Access to research and Open Education in my case.
For various reasons, individual user accounts have never been implemented for our repository and historically it has been administered centrally from the Library. In Symplectic we now have a system that is populated with central HR data; all staff will have an account they can access with their standard user name and password from where they can manage their own research profile including uploading full-text outputs directly to the repository*. In addition, administration by the University Research Office and faculty research administrators will be more easily centralised (particularly for the REF).
* In actual fact this functionality is not yet available in lieu of development work from Intrallect to capture the Atom feed from Symplectic and transform with XSLT to a suitable format for intraLibrary. I think.
One of the clever bits of functionality used to sell the software is automatic retrieval of bibliographic data from online citation databases – we are currently running against various APIs, Web of Science (lite), PubMed and arXiv – but I think this may actually be a bit of a red-herring for an institution like Leeds Metropolitan – at least until more (preferably free) data sources are available (JournalToCs API please!); early testing has shown, at best, it will only retrieve a subset of (the types of) outputs that we will need to record and it will be necessary to manually import existing records (e.g. EndNote) as well as implementing other administrative procedures at faculty level to capture information at the point of publication, especially for book-items, monographs, conference material, reports and grey literature.
More important, I think, to ensure that academic staff actually engage with the software rather than just seeing it as a tool for administrators, is to re-use the data to generate a list of research outputs – a dynamic bibliography – on a personal web-profile which has the potential to dramatically increase the visibility of research including Open Access to full-text.
Developing staff profiles of this type has been something of an obsession of mine for a while; we explored doing so from the repository (using SRU and email address as a Unique Identifier) and did develop a working prototype. Symplectic, however, integrated with central HR data and with its more sophisticated API, should make it much easier, at least from a technical perspective, and we are currently liaising with the central web-team to develop something similar to this example from Keele University – http://www.keele.ac.uk/chemistry/staff/mormerod/ (like us, Keele run Symplectic alongside intraLibrary.)
N.B. From the Symplectic interface, a user is able to “favourite” a research record and a flag comes out in the xml from the API which I understand is used on this page to display “Selected Publications”. DOI is also available from the API to link to the published version and if a user uploads full-text to the repository from Symplectic, this link is also in the xml – the first two records on this page include links to the full-text in Keele’s intraLibrary repository.
Our own Library web-dev Mike Taylor has been looking at the Symplectic API in detail and has put together a couple of prototype pages on a development server and after a meeting this week with a representative of the central web-team I’m reasonably confident we can move forward with this work fairly quickly…though there’s still a bit of a chicken & egg situation in populating the Symplectic database to then be re-surfaced via the API in this way.
There is also the question of whether we might alter our repository policy to become full-text only; one limitation of repositories across UK HE from an original conception (in the arXiv mould) of holding, disseminating and preserving full-text research outputs, is that they have in effect become “diluted” by metadata records for which it has not (yet) been possible to procure full-text or copyright does not permit deposit and “hybrid” repositories like ours, of full-text and metadata typically contain more metadata records than full-text (see figures from the RSP survey here). As I have argued on the UKCoRR blog, I think is makes sense to separate a bibliographic database (in Symplectic) from full-text only in a repository.
N.B. As Symplectic does not have the same search functionality as the repository, this approach has the potential disadvantage that it makes it more difficult to search across the entire corpus of research records (though one potential solution may be along the lines of that implemented by City Research Online which, in my view is rapidly becoming an exemplar of a research management system (Symplectic) + full-text repository (EPrints). Another good example is St Andrews (PURE + DSpace) who presented a case study at “Learning How to Play Nicely: Repositories and CRIS” (video here.)
And what of OER? Along with our EasyDeposit SWORD interface, using OER to resource the refocus the undergraduate curriculum and the soon to be released intraLibrary 3.5 that will enable us to harvest OER from other repositories…for now I think they may be the bits down the back of the settee…