November 30, 2010
by Nick
Recently we submitted a bid to JISC for the Repositories: Take-Up and Embedding strand of Grant 15/10: JISC infrastructure for education and research programme. I don’t know the result of the bid yet but will summarise it here, partly in the spirit of openness exemplified by @chriskeene and Joss Winn and partly because, if we aren’t successful, then I probably won’t much feel like making it public!
Naturally I hope we are awarded the bid but one thing that I have learned from previous bids – both successful and unsuccessful (or job applications for that matter) – is that nothing is ever wasted. We worked hard on this and I’m confident that work will pay off. One way or another!
The bid (abridged)
RepRISE: Reproducing Research Information System Exemplars
Outline Project Description
Institutional Repositories (IRs) are well established in the UK. However, they require continuous development to ensure that they are sufficiently linked to other university systems and to encourage and allow full utilisation and maximum levels of deposit. The RepRISE project will build upon successful JISC funded repository projects in order to incorporate best practice into the Leeds Met repository and embed it into a developing infrastructure to support research management. It will integrate the IR with a commercial CERIF [Common European Research Information Format] compliant CRIS such that metadata/full text can be automatically deposited into the repository while integrating all systemic components with the University LDAP system to ensure outputs are tied to the same unique identifier across the infrastructure. Particular benefits to the community will be to elucidate the challenges of applying established and developing best practice in the context of diverse repository and CRIS software other than employed by the original projects.
Introduction
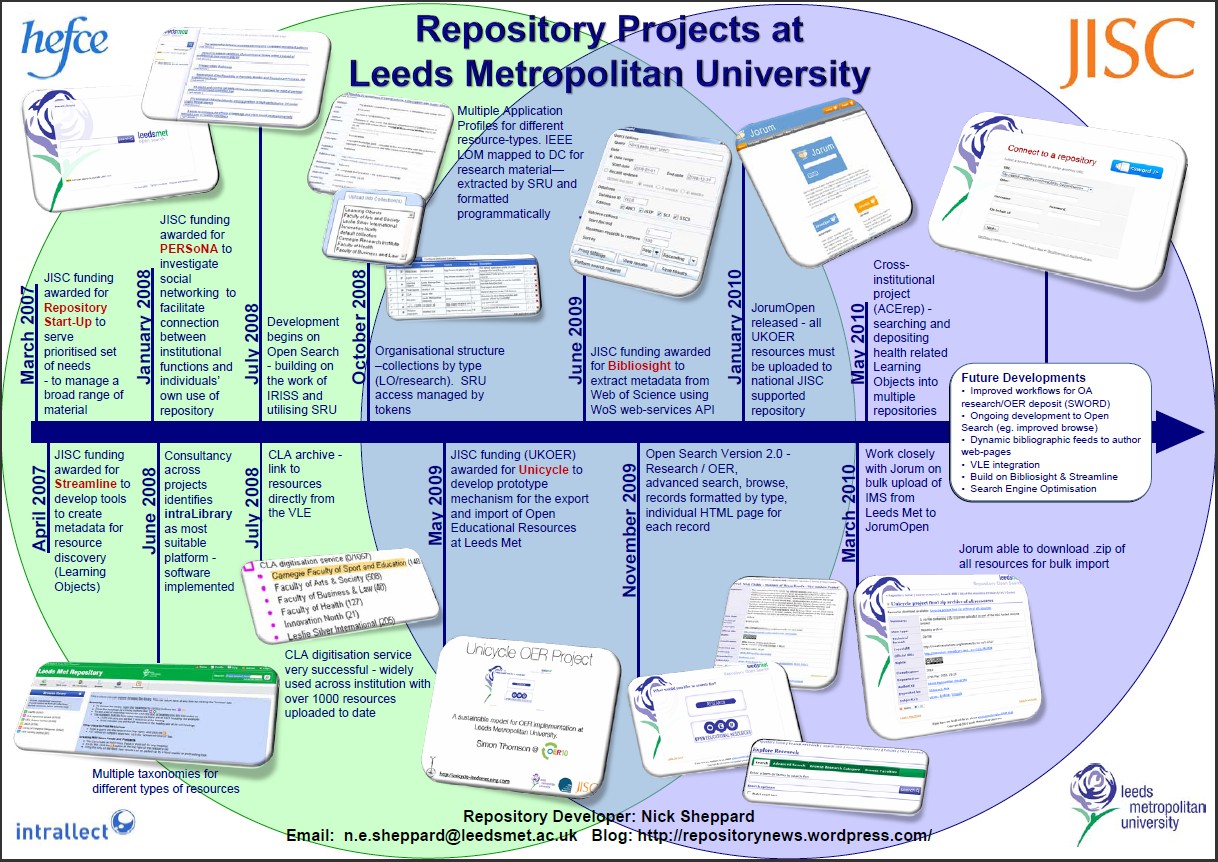
To date, Leeds Metropolitan University has completed four successful repository related JISC-funded projects, establishing an intraLibrary repository which was chosen on the basis that it should support preservation and access to a broad range of materials, including both research and learning and teaching material. We now have a well functioning multi-purpose repository which can be accessed via Leeds Met Repository Open Search at http://repository.leedsmet.ac.uk/main/index.php and currently exposes two main collections to public search – “Research” and “Open Educational Resources”. Through the Unicycle project funded under the e-learning programme and Streamline and PERSoNA funded under the Users and Innovation programme we have developed tools and processes to improve the workflow for users of Research and Open Educational Resources. These projects have successfully engaged users of the repository and started the process of embedding its use into university strategy and procedures. Work is ongoing to backfill the repository with full text and bibliographic records and to develop workflows to integrate with the research life-cycle to capture metadata and full text at the point of publication.
Leeds Metropolitan University’s developing repository infrastructure is representative of JISC supported initiatives since 2005 and Institutional Repositories (IRs) are now well established in the UK and internationally; however, they are often not sufficiently linked to other university systems and tend to be under-used and under-resourced with low levels of full-text deposit and require continuous advocacy to academic staff, the end-users who would benefit most. Increasingly there is a developing relationship and overlap between Open Access research repositories and so called Current Research Information Systems (CRIS) that are increasingly being implemented at universities as well as benefits realisation of the SWORD (Simple Web-service Offering Repository Deposit) protocol to make it easier for academic staff to deposit scholarly outputs into a repository.
A potential additional benefit of a CRIS is that it will facilitate implementation of the CERIF [Common European Research Information Format] data model to better capture and share research information both, within the institution and across collaborating research partners, as well as with research funding bodies. All the major commercial CRIS (Symplectic, Atira Pure, Thomson Reuters’s InCites) are now CERIF compatible and a component of the current proposal will be to investigate the use of CERIF in line with the recommendations of the JISC funded project, Exchanging Research Information in the UK (EXRI-UK)
Examples of CRIS/IR integration include:
- The Universities of St Andrews and Aberdeen who have jointly procured the Pure research information system have carried out a lot of work embedding it with their respective repositories – Pure itself does not preserve full-text research outputs but is able to use the CERIF data model to link to external systems like the IR which, in turn, provides the technology to preserve full text and ensure metadata is harvested by OAI-PMH. In addition, full-text deposit to the repository is mediated through the Pure interface itself giving an integrated system for the user.
- A consortium led by the University of Leeds also comprising Keele University, Queen Mary University of London, University of Exeter and University of Plymouth who are currently working with Symplectic on the RePosit project which aims to “increase uptake of a web-based repository deposit tool embedded in a researcher-facing publications management system.”
- The Enrich project at Glasgow University to establish their Enlighten repository as a comprehensive, University-wide repository and central publications database. It is also seeking to improve staff profiles by linking data from core institutional systems while working to ensure compliance with funders’ open access policies and reporting requirements and improving publicity for research activity and outputs.
Our Deputy Vice Chancellor for Research and Enterprise has emphasised the importance of developing our research infrastructure in order to focus on our areas of strength and continue to develop as we meet the challenges of future research assessments. The DVC is committed to implementing a CRIS at the University and work has already begun to specify institutional requirements of the system and establish capital outlay and ongoing costs to ensure sustainability.
The integration of CRIS/IR systems into an institutional research management infrastructure has the potential to dramatically impact upon advocacy initiatives around repository use and promoting Open Access to research. Using repository data to feed the web-pages of individual academics and schools, for example, will provide an incentive to ensure repository records are comprehensive while the development of web-based interfaces for academic staff to manage their research outputs have the potential to make it easier for them to archive full text.
Deliverables (infrastructure)
- To specify and implement a commercial CRIS
- To integrate the CRIS with the existing Institutional Repository (intraLibrary) such that metadata/full text can be automatically deposited and data can be transferred between the two systems
- To integrate CRIS/repository with the University LDAP system to ensure that outputs are tied to the same unique identifier in all systemic components of the institutional research infrastructure
- To feed repository data to other areas of the University Web site, so that dynamic publication lists can be added to departmental or individual academics’ Web pages
Deliverables (use-cases):
- To produce a detailed report on specific outputs utilised from other CRIS/IR integrations including JISC funded repository projects
- To publish and disseminate a series of use-cases on adapting best practice from other projects focussing particularly on any issues around alternative CRIS/repository software
- To publish and disseminate a series of use-cases on institutional requirements from an integrated CRIS/IR
- To draw up a set of methodologies and approaches for building and engaging user communities within an institution on a subject discipline model
- To develop use-cases exploring advocacy initiatives relating to the developing infrastructure around repository use and promoting Open Access to research
- To investigate the use of the CERIF data model to ascertain if it can be implemented within a timescale to facilitate its use in the Research Excellence Framework (REF)
Value to the JISC community
This project will examine some of the most successful JISC funded repository projects as well as applications and services developed outside JISC funding in order to incorporate best practice into the Leeds Met repository and our developing infrastructure to support research management. The large amount of JISC funds invested in repository development since 2007 and earlier has meant that the value of repositories is now well articulated in the sector; that value, however, is often still potential rather than it is real. There is a wealth of good-practice and many institutional exemplars from which other institutions can learn and employ to improve their own services within the parameters of their particular requirements and existing infrastructure.
In addition to the Enrich and RePosit projects and the repository/Pure integration at St Andrews and Aberdeen, other projects that will inform the current project proposal include:
- Open Research Online (ORO) at the Open University represents a service that is well embedded in the institution’s web-presence, using repository data to feed the web-pages of individual academics and schools.
- CentAUR at the University of Reading has integrated their repository and HR database to ensure that staff are all able to log into the repository with their Reading usernames. The profile data are also the source of an autocomplete suggestion list for names entered into the Author/Creator field. When a name is selected from the list it is automatically associated with a unique ID and email address.
Particular benefits will be to elucidate the challenges of applying established and developing best practice in the context of diverse repositories, CRIS software and internal infrastructure over and above those employed by the original projects and including the potentially different institutional mission regarding research and the relationship between teaching and research.
Glasgow, ORO, Leeds, Plymouth and Reading all use EPrints software, the de facto open source OA research platform while St Andrews and Aberdeen use DSpace, another open source repository platform typically also dedicated to research management; Exeter uses Open Repository, a hosted solution from BioMed Central also based on DSpace while Keele University, with intraLibrary, is the only institution to use the same commercial platform as Leeds Met. Keele also use Symplectic, a leading commercial CRIS, and have already worked with their commercial partners in order to link the two systems so that a full text and its bibliographic record can be pushed from Symplectic directly into intraLibrary; this project would allow us to build upon that work, either with Symplectic or another commercial CRIS, while also exploring the integration of the other institutional exemplars with intraLibrary.
As referred to above, a component of this project will also be to investigate the viability of integrating the CERIF data model into an institution where the existing research infrastructure is limited and within a timescale to facilitate its use in the Research Excellence Framework (REF).
Workplan
At Leeds Metropolitan University, there is a well established relationship between the University Research Office and the Repository Development team which will help to ensure effective communication throughout the proposed project. As outlined above, the Deputy Vice Chancellor for Research and Enterprise is committed to institutional investment in a commercial CRIS with work already underway to identify and procure a suitable system; Workpackage 1, therefore, is effectively already underway and, as such, will constitute the foundation of the current proposal allowing us to integrate the chosen system with our repository infrastructure more rapidly and more effectively than would otherwise be the case.
The project will be overseen by a Project Director who will hold regular meetings with the Deputy Vice Chancellor for Research and Enterprise in order to keep him up to date with progress. The team will work on the adaptation of the SCRUM project management approach that they have used successfully in completing two earlier JISC funded projects – Bibliosight and JANUS and most recently in the ongoing HEFCE funded ACErep project; with monthly meetings of the core project team, with other stakeholders and technical advisors invited to meetings as necessary.
Workpackages
Submitted
Success criteria, benefits realisation and sustainability
- That a commercial CRIS is implemented and integrated with the Institutional Repository (intraLibrary), and university LDAP system such that metadata/full text can be automatically deposited from the CRIS into the repository and all outputs are tied to an author unique identifier across the institutional research infrastructure.
- Data feeds from the repository are exposed to other areas of the University Web site, so that dynamic publication lists can be easily added to departmental or individual academics’ Web pages.
- The CERIF data model is implemented and may be extended across the research infrastructure that has been tested in the context of the REF.
- That skills and knowledge pertaining to research management using the CERIF data model are transmitted to relevant staff including URO, Repository Team and Academic Staff
- That the team has published/disseminated a set of use-cases on adapting best practice from other projects focussing particularly on issues around alternative CRIS/ repository software.
- That the team has compiled a set of methodologies and approaches for building and engaging user communities within an institution on a subject discipline model.
- That the team has developed new advocacy initiatives relating to the developing infrastructure around repository use and promoting Open Access to research
Sustainability of the project following completion is underpinned through the alignment of the project with the plans of the Deputy Vice Chancellor for Research and Enterprise to build an integrated research management system across the University. This project represents an initial stage of that, and will be built upon over the medium term.
IPR
The project team will ensure tools and systems used in the project are used with the agreement of their creators and third parties where permissions are required for their use in this context. All project outputs will be publicly and widely disseminated for reuse by the community with appropriate IPR statements clearly stated.
Risk register
Submitted
Engagement with the community
As a high profile initiative headed by the Deputy Vice Chancellor for Research and Enterprise, the implementation of a commercial CRIS at Leeds Metropolitan University will be communicated within the institution through a centralised communication policy; institutional stakeholders will be actively involved in developing the infrastructure, through their feedback and participation in the development of use cases.
In addition to engaging institutional stakeholders and providing feedback to JISC, a key aim of the proposal is to disseminate our experiences to the wider community particularly in the context of implementation with alternative software and systems; this will be achieved by utilising social networking technologies as well as traditional live dissemination events; a blog will be included on the project website with cross-dissemination via Twitter, an approach that has been carried out very successfully for previous projects at Leeds Met – see https://repositorynews.wordpress.com/ and http://acerep.wordpress.com/. Members of the project team will use the blog to report progress and engage in discussion around project aims and objectives, milestones, any challenges the project might meet, and any other project activities.
The project team also has established links with the Repository Support Project (RSP) and is represented on the committee of the UK Council of Research Repositories (UKCoRR) an independent body for repository managers, administrators and staff in the UK that provides a forum for discussion and exchange of experience and represents the views and concerns of those who work with repositories in organisational, policy and strategic development. Both organisations hold regular meetings and events which will provide valuable dissemination opportunities.
Opportunity will also be sought to contribute to relevant publications. Project Officer Nick Sheppard has already published a detailed summary in Ariadne of the “Learning How to Play Nicely: Repositories and CRIS” event examining integrated, systemic approaches to research information management organised by the Welsh Repository Network and supported by JISC and ARMA at Leeds Metropolitan University in May 2010.
Budget
Submitted
Previous experience of the project team
Submitted